指標說明與數(shù)據來源
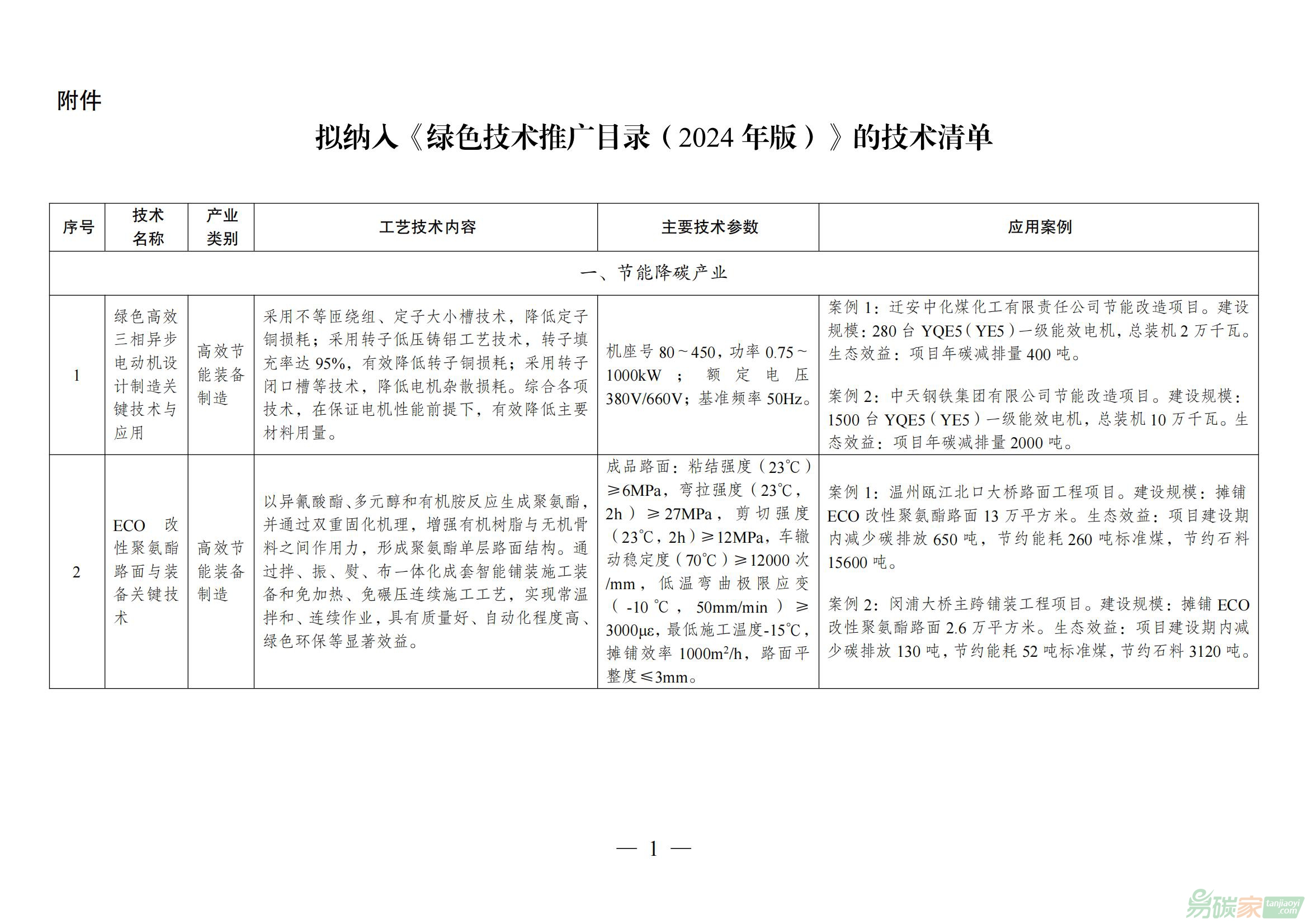
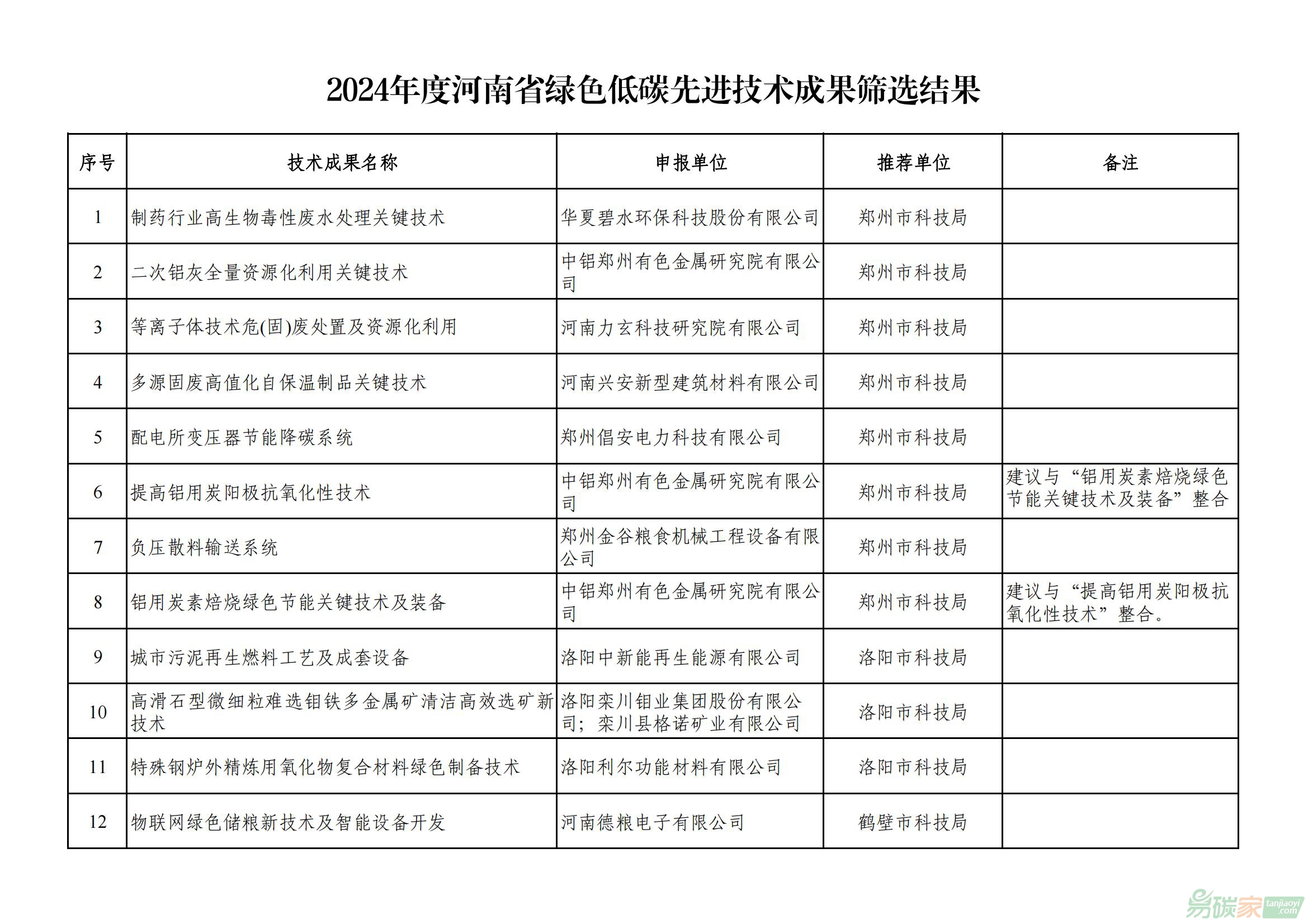
二、指標說明與數(shù)據來源
(一)指標說明
第一,
碳排放指標。能源部門通常是溫室氣體排放中的最重要部門,在發(fā)達國家,其貢獻一般占CO2排放量的90%以上和溫室氣體總排放量的75%。根據《中華人民共和國氣候變化初始國家信息通報》中的數(shù)據,能源活動是中國最主要的CO2排放源,1994年中國能源活動的CO2排放量在全國CO2排放總量中占90.95%。因此,本文主要研究中國與能源活動有關的CO2排放,包括煤炭、石油、天然氣等三種化石燃料消耗。
中國碳排放量采用以下公式進行估算:
(1)
其中,C為碳排放量;E為中國一次能源的消費總量;Fi為i類能源的碳排放系數(shù);Si為i類能源在總能源中所占的比重。其中一次能源消費總量E和比重Si的計算均采用發(fā)電煤耗計算法,數(shù)據取自于《中國能源統(tǒng)計年鑒1989》和《中國能源統(tǒng)計年鑒2009》。通過查閱有關文獻,收集有關能源消耗的碳排放系數(shù)并進行比較計算,最終取平均值確定為各能源消耗碳排放系數(shù)Fi。
第二,產業(yè)結構重型化指標。產業(yè)結構重型化是指在一國經濟發(fā)展中,工業(yè)制造業(yè)由以輕工業(yè)為中心轉變?yōu)橐灾毓I(yè)為中心,重工業(yè)在國民經濟中占據主導地位的階段。本文用重工業(yè)產值的變化來表示產業(yè)結構重型化發(fā)展情況。1978-2008年的重工業(yè)產值來源于歷年《中國工業(yè)經濟統(tǒng)計年鑒》。為了分析的可比性,重工業(yè)和輕工業(yè)均采用《中國工業(yè)經濟統(tǒng)計年鑒》中給出的定義,重工業(yè)是指為國民經濟各部門提供物質技術基礎的主要生產資料的工業(yè),輕工業(yè)是指提供生活消費品和制作手工工具的工業(yè)。
(二)數(shù)據來源及處理
本文以1978年至2008年我國重工業(yè)產值和碳排放量為分析的基礎數(shù)據,重工業(yè)產值和碳排放量分別用ZGY和TPF表示。由于數(shù)據的自然對數(shù)變換不改變原來的協(xié)整關系,并能使其趨勢線性化,消除時間序列中存在的異方差現(xiàn)象,對兩個變量取自然對數(shù),分別表示為LZGY和LTPF。圖1是1978年到2008年間我國重工業(yè)產值和碳排放量變化趨勢。從圖中可以看出,考察期內,我國重工業(yè)產值和碳排放量的走勢基本一致,尤其是2000年以后,兩者的變化趨勢幾乎完全一致,都經歷了一個上升的過程。這說明,在我國重工業(yè)發(fā)展和碳排放量之間存在著長期對應關系。本文通過運用時間序列動態(tài)均衡的分析方法,在單位根檢驗、協(xié)整檢驗的基礎上建立了誤差修正模型,以此說明我國產業(yè)結構重型化與碳排放的長期均衡關系和短期動態(tài)關系。
三、實證檢驗結果
(一)單位根檢驗
在實際經濟運行中,經濟變量的時間序列數(shù)據很少是平穩(wěn)的,若采用傳統(tǒng)普通最小二乘法進行回歸分析,很容易導致“謬誤回歸”。從圖1我們也可以看出,1978-2008年間,我國重工業(yè)產值增長和碳排放總量均具有明顯的上升趨勢,顯示出不平穩(wěn)性。因此,為了保證回歸的真實性,本文使用ADF法對變量LZGYt和LTPFt進行平穩(wěn)性檢驗,檢驗形式由序列圖確定,滯后階數(shù)根據SC最小準則確定,具體檢驗結果如表2所示。
表2的結果顯示,對數(shù)序列LZGY、LTPF的ADF值均大于1%的顯著性水平的臨界值,不能拒絕存在單位根的假設,即序列都是非平穩(wěn)的;但其一階差分在1%的置信性水平下拒絕了原假設,說明是平穩(wěn)的。因此可以判定LZGY、LTPF都是一階單整的,它們都是I(1)序列,滿足變量協(xié)整的條件,即LZGY和LTPF很可能存在協(xié)整關系。
(二)協(xié)整關系檢驗
雖然一些經濟變量的本身是非平穩(wěn)序列,但是它們的線性組合卻有可能是平穩(wěn)序列,這種平穩(wěn)的線性組合被稱為協(xié)整方程且可被解釋為變量之間的長期穩(wěn)定的均衡關系。目前最常用的協(xié)整分析方法主要有Engle-Granger(EG)的兩步法以及Johansen和Juselius(JJ)的極大似然法。前者適合于雙變量的協(xié)整檢驗,本文采用此方法進行檢驗。
首先用LZGY對LTPF進行回歸,即建立如下計量方程:
(2)
采用OLS法對式(2)進行估計,得:
(3)
R2=0.977586;Adj-R2=0.976813;F=1264.835***;D-W=0.188229
式中,括號內數(shù)字為t統(tǒng)計量值,***表示在0.01水平上顯著,et為回歸殘差。
式(3)的D-W值指示誤差項存在正自相關,因此,參數(shù)估計值顯著性檢驗失效,從而預測值盡管是無偏的,但卻不是有效的。為了消除誤差項的序列相關性,我們建立如下(p,q)階回歸分布滯后模型:
(4)
其中,p、q分別為LTPF和LZGY的最大滯后階數(shù)。依據英國計量經濟學家亨德瑞等人倡導的“從一般到簡單”的Hendary/LSE建模方法,考慮到采用的是年度數(shù)據以及自由度的約束,我們選擇最大滯后階數(shù)p、q均為2,建立一般模型,然后利用Wald檢驗和t檢驗,依次剔出一個或多個系數(shù)不顯著的變量,進行模型簡化,并結合模型選擇統(tǒng)計量(AIC和SC)選擇一個最優(yōu)的模型作為最終模型,估計結果如下:
(5)
R2=0.996901;Adj-R2=0.996384;F=1929.861***;D-W=1.441374
式中,括號內數(shù)值為t統(tǒng)計量值,**、***分別表示在0.01、0.05水平上顯著。
接下來需要對(5)式的殘差項進行序列相關性檢驗。由于方程的解釋變量存在被解釋變量的滯后項,此時D-W值就不能作為判斷回歸方程的殘差是否存在序列相關的標準,如果殘差序列存在序列相關,那么,顯著性水平、擬合優(yōu)度,F(xiàn)統(tǒng)計量將不再可信。這種情況下可以利用LM統(tǒng)計量進行檢驗。采用LM統(tǒng)計量進行檢驗(p=2),得到結果如下:
LM統(tǒng)計量顯示,F(xiàn)統(tǒng)計量和T×R2統(tǒng)計量均小于在10%的顯著性水平下的臨界值,因此無法拒絕原假設“直到p階后不存在序列相關”,即可以認為回歸方程的殘差序列不存在序列相關性,因此用方程(5)來分析產業(yè)結構重型化對碳排放的影響。
由式(5)計算得誤差項:
(6)
對該誤差項進行平穩(wěn)性檢驗,如果et是平穩(wěn)的,則說明LTPF和LZGY之間具有協(xié)整關系。仍采用ADF單位根檢驗方法,選擇既無趨勢項也無常數(shù)項,檢驗時采用SC最小準則自動選擇滯后階數(shù)為5。最終檢驗結果見表4。
殘差序列et的ADF檢驗結果表明,ADF檢驗統(tǒng)計量小于1%顯著水平下的臨界值,說明殘差et為平穩(wěn)序列。由此可以得出結論,我國產業(yè)結構重型化和碳排放之間存在協(xié)整關系。而為了得到二者之間的長期均衡關系,只需令:LTPFt=LTPFt-1=LTPFt-2=LTPF*,LZGYt=LZGYt-1=LZGY*,并代入(5)式,整理后得到:
(6)
(6)式即為產業(yè)結構重型化與碳排放之間的長期均衡關系,它表明,重工業(yè)產值每提高1%,碳排放量就會提高0.278141%。這表明產業(yè)結構重型化加大了我國的碳排放量。



 5群
5群