2019-7-5 13:41 來源: 深圳市生態環境局
[詳細]
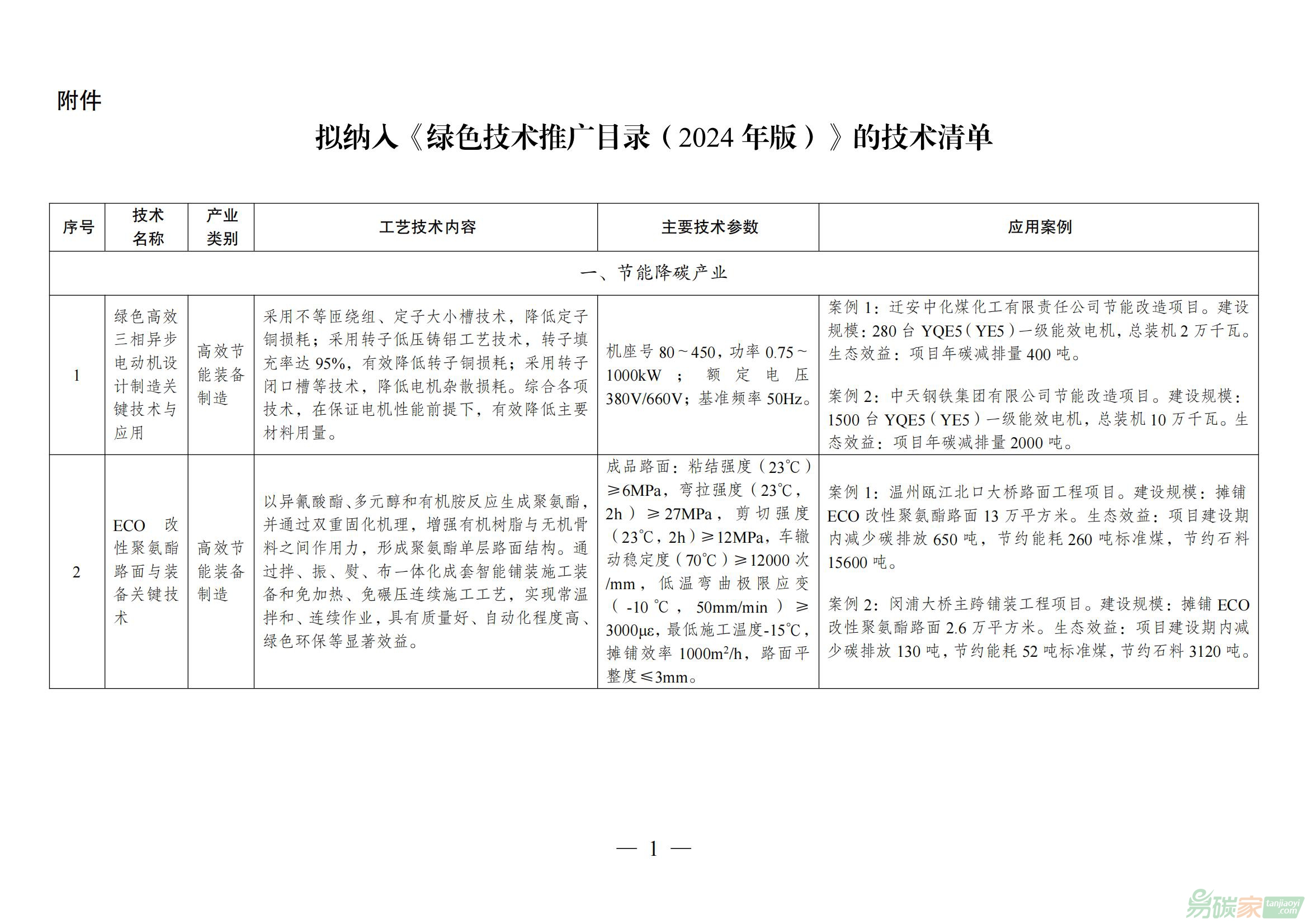
擬納入《綠色技術推廣目
廣州市氫燃料電池汽車行
廣州市餐飲外賣行業無需
《中國應對氣候變化的政
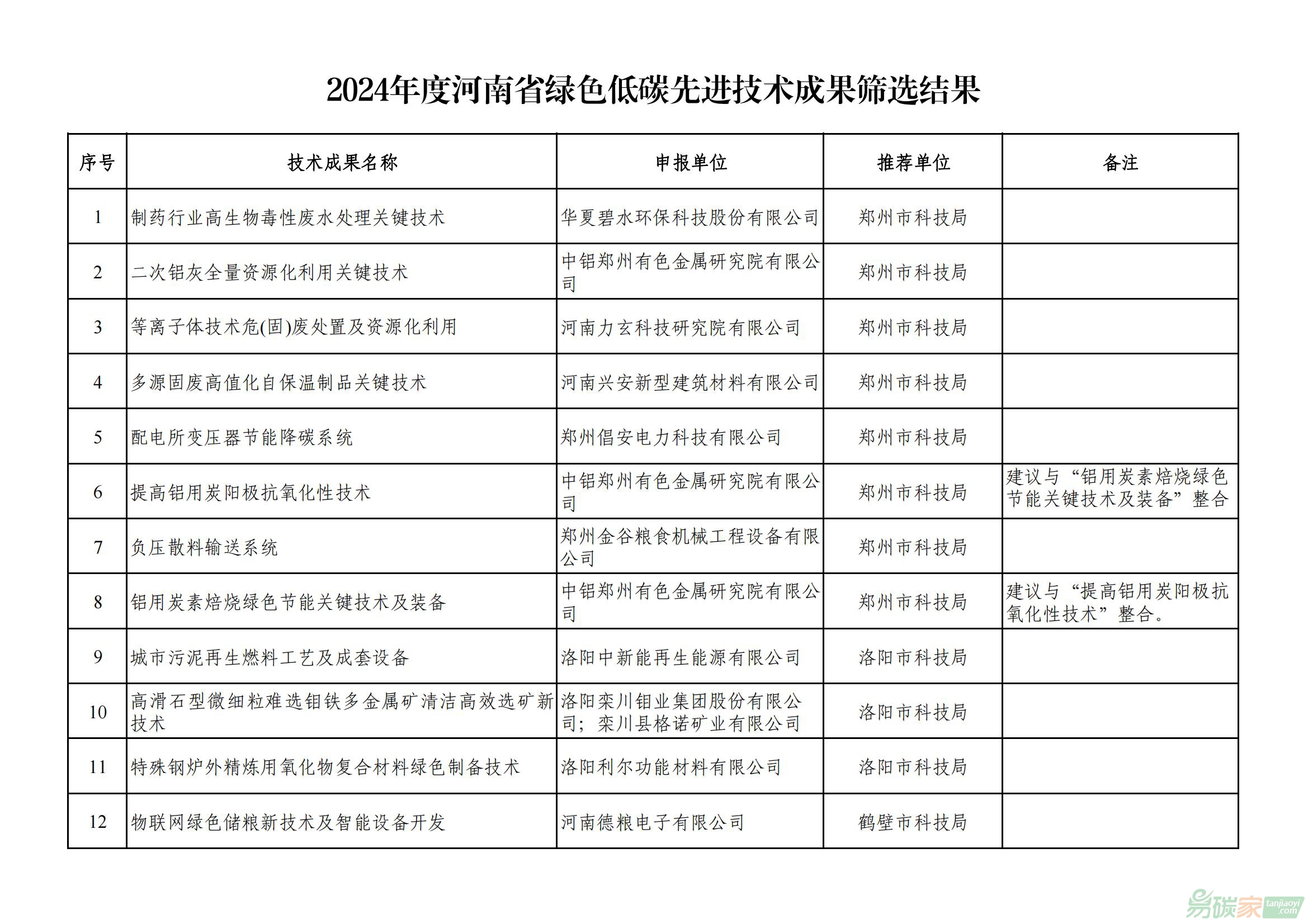
關于2024年度河南省綠色
關于印發《錫林郭勒盟工
批準單位:中華人民共和國工業信息部 國家工商管理總局 指導單位:國家發改委 生態環境部 國家能源局 各地環境能源交易所
聯系方式:137-0100-7233
Copyright?2014 碳交易網 Tanjiaoyi.com. All Rights Reserved
國家工信部備案/許可證編號-京ICP備12050358號-1 中國碳交易QQ群: 6群 5群